I wanted to flag a potential scalability observation, and keen to have further discussions.
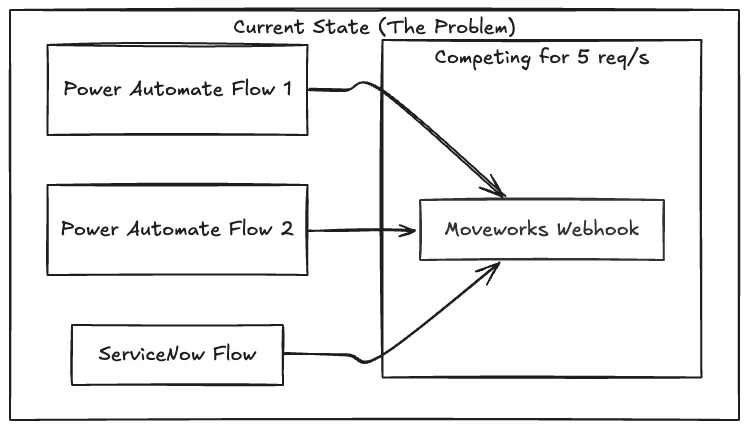
With the introduction of Ambient Agents, more systems are integrating with Moveworks via webhooks. As we continue to add plugins across multiple systems, the volume and frequency of inbound calls will increase significantly, which raises the risk of hitting rate limits (HTTP 429 errors).
To illustrate with a concrete example:
- One Power Automate flow pulls data from Intune and sends device status alerts to Moveworks users.
- A second Power Automate flow also pulls data from Intune and sends device status alerts to Moveworks users.
- A ServiceNow flow sends SAM reclamation alerts to Moveworks users.
If these plugins are scheduled to run daily, the cumulative execution time becomes quite long. While these jobs are running, additional webhook calls from external systems can still occur, increasing the likelihood of rate limiting.
We’ve already implemented a 10-second delay between each API call across all three flows. However, this approach doesn’t give us sufficient control to reliably prevent rate limit errors, especially as usage scales.
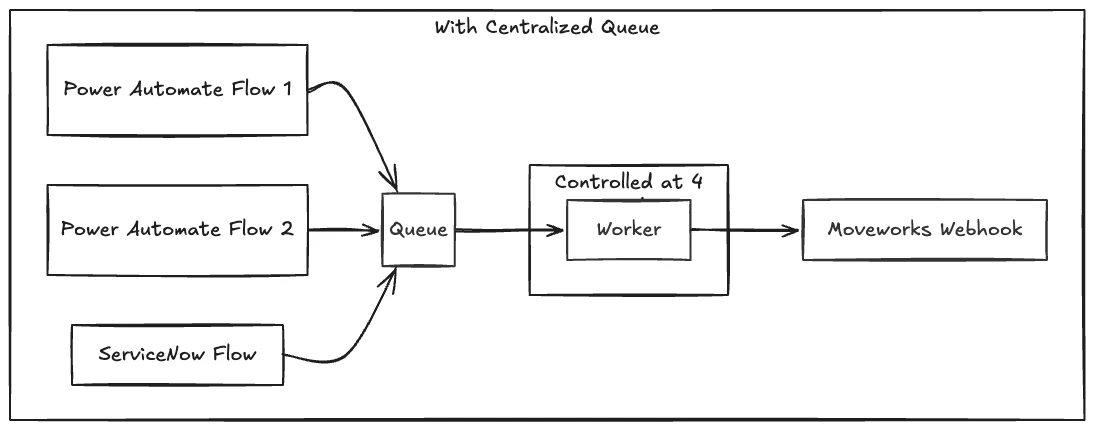
Would be interested to get an initial perspective on how we might approach this more robustly from a platform or architecture standpoint.