
Hello Community!
I wanted to share a useful architecture for implementing an Autonomous Ticket Quality Assessment Agent using Moveworks. This can be done using any ITSM, but this example is specific to ServiceNow. This approach enables teams to run consistent, scalable QA evaluations across assignment groups, store results directly in ServiceNow, and proactively notify QA leaders with actionable insights.
The Use Case: Autonomous Ticket Quality Assessment
The goal is to evaluate the quality of resolved ServiceNow tickets on a recurring basis and provide structured feedback at both the agent and assignment-group level.
On a weekly scheduled trigger, the system:
- Evaluates tickets by assignment group
- Scores each ticket across standardized QA dimensions defined by the organization
- Stores results back in ServiceNow
- Generates a summarized report for QA managers to review
The Solution: AI-Driven Ticket QA
This architecture uses Agent Studio to combine HTTP Actions, LLM Actions, System Triggers, and ServiceNow persistence to create a closed-loop QA system. Using Moveworks’ built-in LLM Actions enables secure and efficient access to Moveworks’ underlying models for agent reasoning and decision-making. Below is a high-level overview of how this can be implemented in Agent Studio.
Architecture Flow
1. Scheduled Job Triggers Plugin to Retrieve Assignment Groups
- Retrieves the list of ServiceNow assignment groups to evaluate
(sys_user_group)
2. Pull Weekly Tickets Per Assignment Group
- For each assignment group, fetch tickets created or updated during the evaluation window using the group’s sys_id
(incident)
3. Score Each Ticket
For every ticket retrieved, Moveworks runs an LLM-powered QA evaluation using the following built-in LLM Action:
- mw.generate_structured_value_action
This produces a structured scorecard with 1–5 ratings and justifications across five QA dimensions:
- Classification Accuracy
Priority, impact, urgency alignment, and correct assignment group/category
- Ticket Documentation
Field completeness, clarity, and work/resolution notes quality
- Customer Communication
Timeliness and consistency of updates to the requester
- Categorization
Correct category and subcategory selection
- Professionalism & Ownership
Tone, stagnation avoidance, and accountability
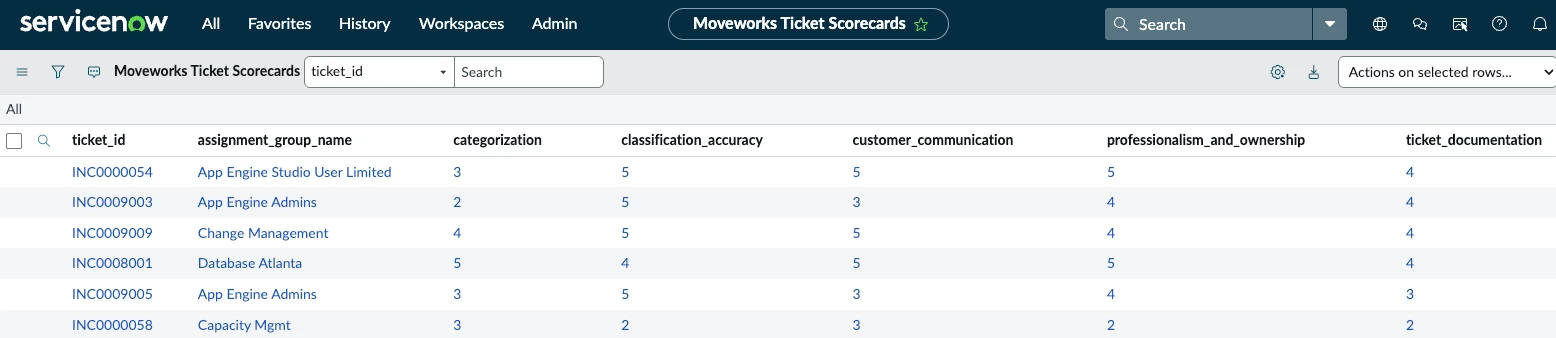
4. Save Ticket QA Scores in ServiceNow
- Each ticket’s QA scorecard is written back into a custom ServiceNow table for review and historical tracking
(u_moveworks_ticket_scorecard)
📸 (QA scorecard attached to a ServiceNow ticket)
Assignment Group Reporting & Insights
5. Generate Weekly Assignment Group Summary
Once all ticket scorecards for an assignment group are completed, Moveworks generates a group-level summary using the following built-in LLM Action:
- mw.generate_text_action
The summary highlights:
- Average and recurring scoring patterns
- Common quality gaps
- Notable strengths and wins
📸 (Moveworks analysis on ticket scorecards.)

📸 (Recommended actions for improvement)

Proactive QA Notifications
6. Notify the QA Lead
- The system looks up the configured QA recipient
- Sends the assignment-group summary via an Agent Studio notify
This ensures QA leaders receive timely, actionable insights automatically, without needing to manually compile reports.
Edge Case Handling: No-Ticket Weeks
- If an assignment group has no tickets during the evaluation period, the system:
- Skips ticket scoring and summarization
- Continues processing remaining groups
- Avoids sending empty or unnecessary notifications
- Skips ticket scoring and summarization
Why This Architecture Works Well
- ✅ Scales QA across multiple assignment groups
- ✅ Ensures consistent evaluations using structured LLM scoring
- ✅ Keeps ServiceNow as the authoritative data source
- ✅ Delivers proactive insights to QA leaders
- ✅ Minimizes ongoing manual effort
This approach creates a robust, automated QA feedback loop that drives continuous improvement across support organizations.
Please comment below if you have questions, ideas for enhancements, or have implemented something similar!
