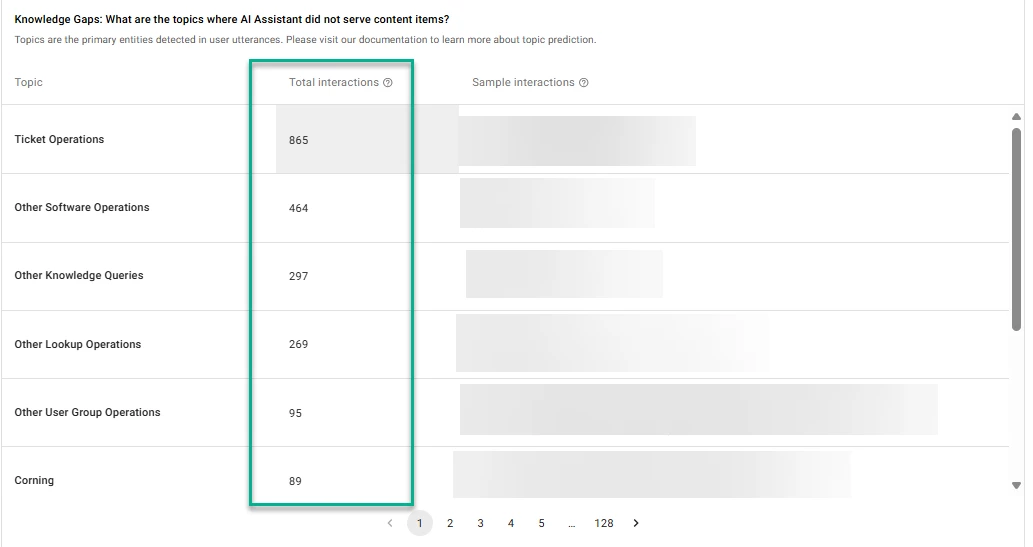
As part of our ongoing efforts to enhance our customer support and improve our knowledge base, I am exploring efficient ways to analyze raw interaction data. Specifically, I am focused on identifying knowledge gaps by reviewing instances where our chatbot did not provide a direct answer and directed users to "Get Help" options.
Currently, the volume of these interactions is substantial, making manual analysis time-consuming—often taking several hours to sift through thousands of rows. Despite filtering the raw interactions and utilizing my companies internal GPT model, I have yet to find a scalable and effective method to streamline this process.
It’s important to note that we are not setup for Knowledge Writer or or using similar automated tools for this task; everything is done manually. I would greatly appreciate hearing from anyone who has developed efficient, automated, or innovative approaches for:
- Quickly identifying knowledge gaps
- Effectively filtering and analyzing the raw interactions
- Using AI tools or other solutions to expedite this process
Your insights and experiences could greatly benefit my efforts to improve our services and knowledge management. Please feel free to share your best practices, tools, or suggestions.