

Hey,
Your plugin didn't break in production. It was always going to degrade after a few turns. You just never had a conversation long enough to notice.
By turn three or four, the reasoner — the agentic reasoning engine that orchestrates your plugin's conversation — starts repeating questions, hallucinating field values, forgetting what the user said two messages ago. The config didn't change. The context window filled up. Before your user said a single word, your plugin had already consumed thousands of tokens in slot descriptions, system prompts, action schemas, and resolver metadata. Every turn after that is a fight for what's left.
We covered the architecture fix for chained actions in Issue #5. Today: the two places most builders waste context without realizing it.
The Context Budget
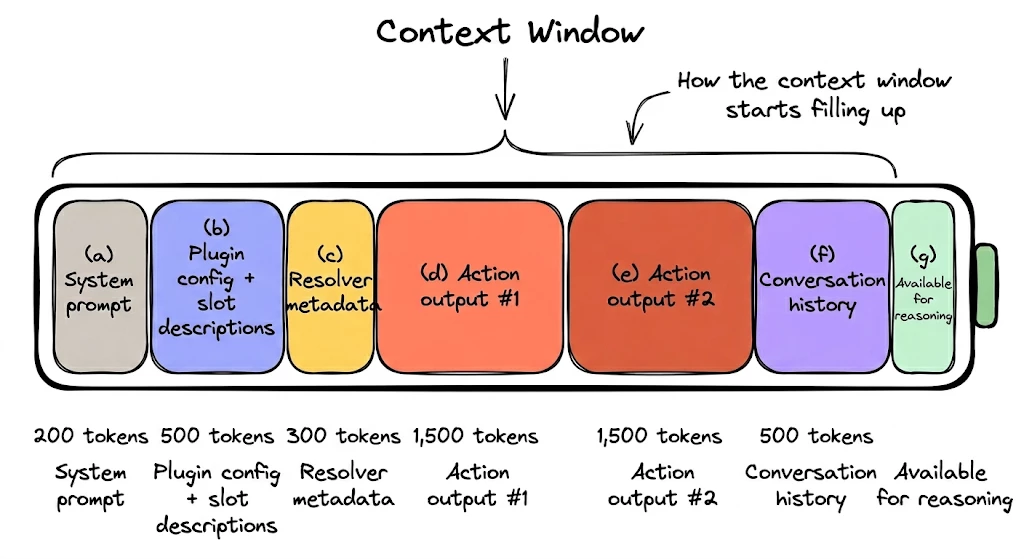
Every plugin has a context budget: the total information the reasoner can hold in working memory during a conversation. Slot descriptions, action outputs, conversation history, system instructions. All competing for the same finite window; builders fill it with noise before the conversation even starts.
What fills the context window
Each action activity returns output that gets added to the reasoner's context window and stays there for the rest of the conversation. The context growth table from the Golden Rule docs assumes a typical API response: 10-20 fields, a few hundred characters per field, maybe a KB or two of JSON.
| Chained Actions | Estimated Context Growth | Latency Impact |
|---|---|---|
| 1 | ~2-5 KB | Baseline |
| 2 | ~4-10 KB | Noticeable |
| 3 | ~6-15 KB | Significant |
| 4 | ~8-20 KB | Doubles |
If your action returns a full ServiceNow incident with 50+ fields, nested comments, and audit history, you're blowing past these numbers on a single call. That's just action outputs. Add slot descriptions, system prompts, and conversation history, and you're burning through your budget before the reasoner even starts reasoning about the user's actual request.
Builders who've been burned by production context limits learn this fast. Everyone else discovers it when their users start complaining.
Two patterns account for most of the waste.
Bloated slot descriptions
Slot descriptions tell the reasoner what a slot represents. They're semantic labels, not rule engines. But builders keep stuffing validation logic, formatting rules, and behavioral instructions into them.
Here's what it looks like in the wild:
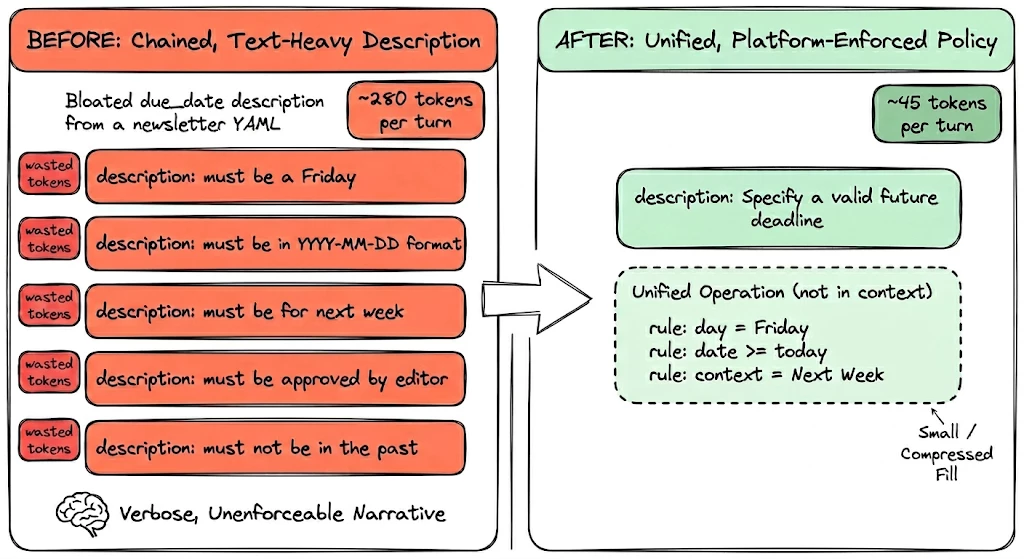
# Bloated slot description — every character here burns tokens
- name: due_date
description: |
The date when the task is due. MUST be in YYYY-MM-DD format.
The date CANNOT be in the past. If user provides a past date,
reject it and ask again. The date should be within the next
90 days. If the user says "tomorrow", calculate the date.
data_type: string
# ← 5 lines of rules the reasoner can't enforce
# ← These tokens load into context on EVERY turn
# ← None of this gets enforced — it's just noiseThat description is 280+ characters the reasoner reads on every turn but can never enforce. Rules packed into descriptions aren't enforced. The reasoner might ignore them or hallucinate compliance. Every character consumes tokens in every reasoning call.
The fix: description says what, validation policy says how.
# Clean description + validation policy
- name: due_date
description: 'The target completion date for this task.'
data_type: string
validation_policy:
rule: $PARSE_TIME(value) >= $TIME()
error_message: 'Due date must be today or in the future'
# ← Description: 1 line, says what the slot IS
# ← Validation: deterministic, enforced by the platform
# ← Reasoner never sees the rule — it just worksOne line instead of five. The validation policy runs deterministically on the platform. The reasoner never processes those rules.
Format hints like "Expected format: YYYY-MM-DD" are fine in descriptions. Behavioral logic ("if the user says X, do Y") is not. Move those to validation policies, decision policies, or resolver strategies.
Rule: Descriptions say what, not how.
Reasoner calls hiding in your output mapper
Your action returns a big JSON payload and you only want a few fields. So you use system_instructions in the output mapper to ask the reasoner to pick them out:
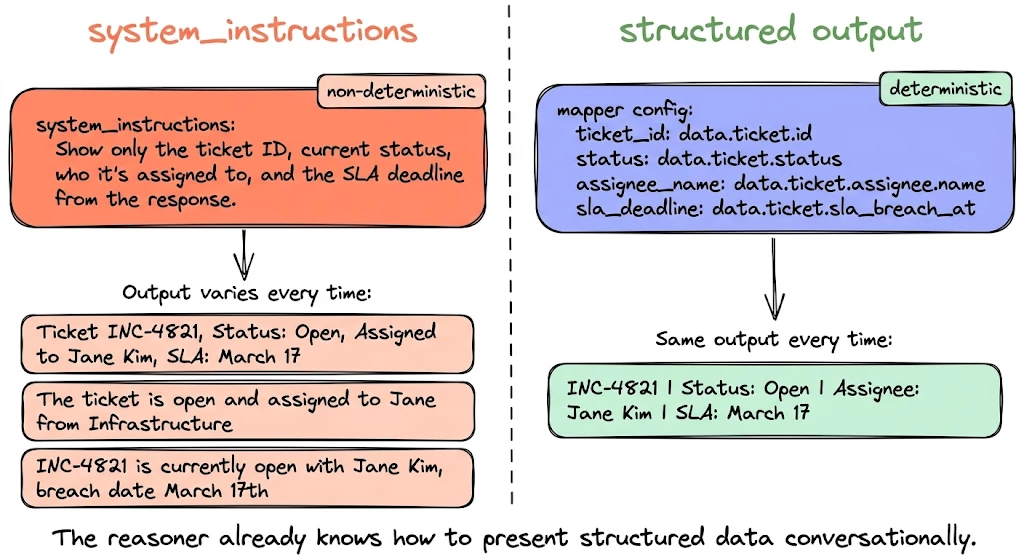
# system_instructions doing the field selection — unreliable
output_mapper:
summary:
system_instructions: >
Show only the ticket ID, current status,
who it's assigned to, and the SLA deadline
from the response.
# ← The reasoner decides what to include and how
# ← Non-deterministic: different output every time
# ← Might hallucinate fields or drop the SLA entirelyWhen system_instructions is doing the field selection, the reasoner decides what to show. That's non-deterministic; you get different output every time. Sometimes the user sees: "Ticket INC-4821, Status: Open, Assigned to Jane Kim, SLA: March 17." Other times: "The ticket is open and assigned to Jane from Infrastructure." Same action, same data, different result.
The fix: let the structured output handle field selection. Map the fields you want directly.
# Structured output mapper — deterministic, reliable
output_mapper:
ticket_id: data.ticket.id
status: data.ticket.status
assignee_name: data.ticket.assignee.name
sla_deadline: data.ticket.sla_breach_at
# ← Fields mapped directly — no ambiguity
# ← Same output every time, guaranteed
# ← The reasoner already knows how to present structured data conversationallyFour fields, mapped directly. Same output every time. The reasoner already knows how to present structured data conversationally; you don't need system_instructions to do that work for you.
The nuance: system_instructions is fine inside a structured output for formatting and tone ("present dates as Month Day" or "use bullet points"). The problem is when system_instructions is doing the field selection — deciding what to show instead of how to show it. That's where it breaks down.
Rule of thumb: Three rules for a lean context budget: (1) descriptions say what, not how; (2) map fields directly, never with system_instructions; (3) chain actions inside compound actions, not between activities (the Golden Rule from Issue #5).
Your plugin should hold a 20-turn conversation without losing the thread. If it can't, one of these two patterns is probably why.
Quick Hits
→ Image URLs in Notifications — Notifications can now render image URLs inline. Pass an image link and the user sees it directly in the message.
→ LLM Fundamentals — New docs section covering the reasoning engine from the ground up. If you're building plugins and haven't read this yet, start here.
→ Best Practices Guide — The Golden Rule, context budgets, slot descriptions, output mappers. New section consolidating everything we've been covering in this newsletter.
Worth Reading
→ Slots Deep Dive — The full breakdown of how slots work under the hood, from type selection to resolver strategies.
→ Lost in the Middle: How Language Models Use Long Contexts — This is why your second chained action's output gets ignored.
→ Building Durable AI Agents: A Guide to Context Engineering — The framing of context as a "compiled view over structured state" rather than a mutable string buffer is worth internalizing.
→ Architecting Efficient Context-Aware Multi-Agent Framework for Production — Different platform, same physics; they name "lost in the middle" as a failure mode of naive context stuffing.
Join the Community
Building plugins and want to compare context budgets? The community has builders sharing their before/after configs. Office Hours have been a cookout. Sign up here.
-- Kevin
Developer Advocate @ Moveworks | Agent Studio
P.S. Reply if you've ever watched the reasoner forget something the user said 30 seconds earlier. I'm collecting the worst ones for a future deep dive.