
Problem
A common challenge in Agent Studio is how to serve grounded answers from public-facing documentation without building a full external ingestion pipeline.
Teams often want the bot to answer questions using content that already lives on public websites, but they also want the experience to stay
- grounded in source material rather than general model knowledge
- transparent, with citations or traceability
- lightweight to implement and maintain
- targeted enough to return useful answers without introducing too much ambiguity
This becomes especially relevant when the source content is public documentation, such as help centers, product docs, compliance pages, or accessibility documentation.
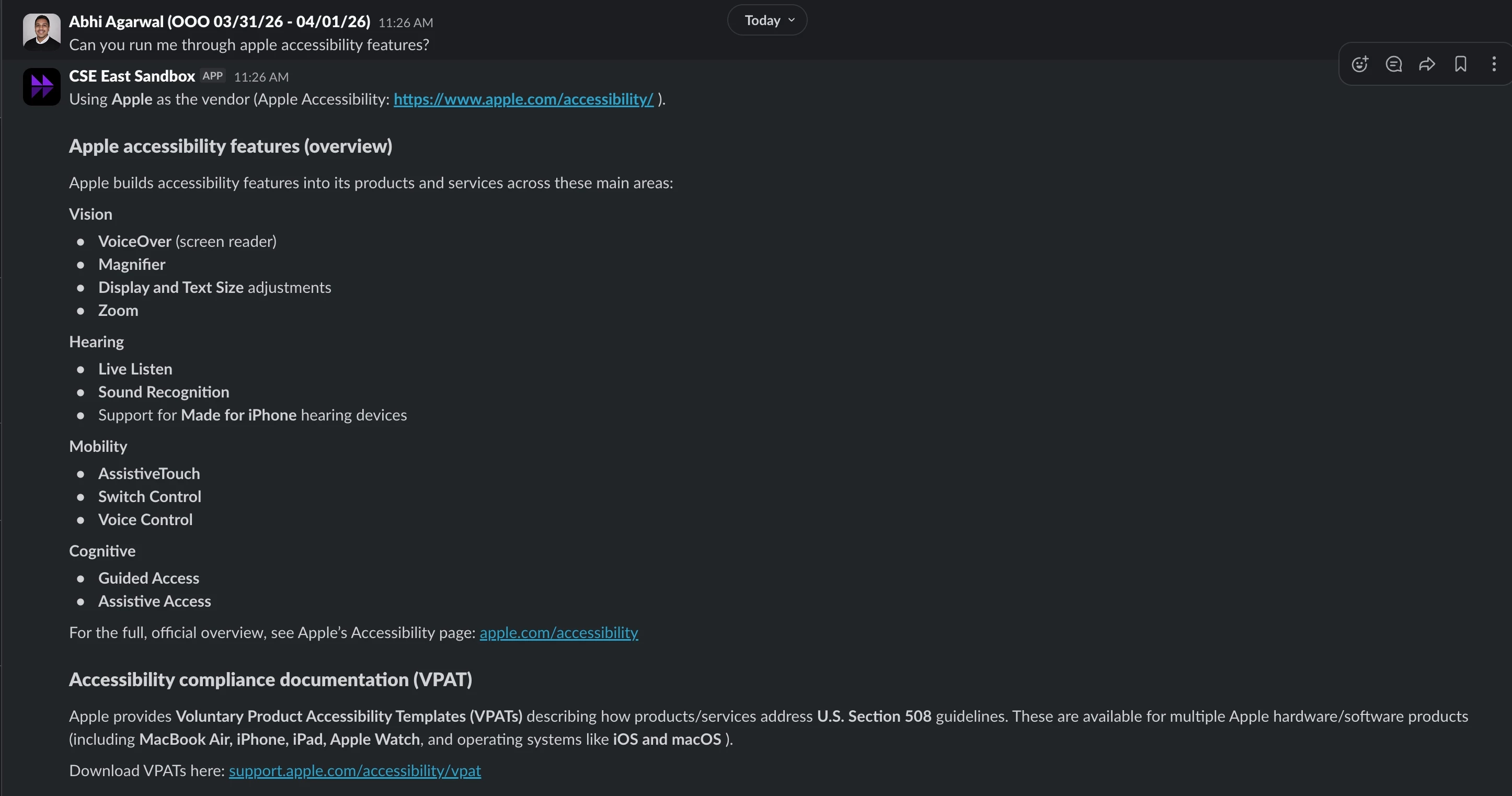
A good example is accessibility content. A user may ask about a specific capability such as Teams closed captioning, and the desired behavior is for the bot to answer from the correct Microsoft accessibility page rather than from broad web knowledge.
The architectural question is: how do you reliably route the user to the right public source page and generate a grounded answer, while keeping the implementation manageable inside Agent Studio?
Solution
A practical pattern is to combine Agent Studio, Live Search LLM actions, and URL resolution logic so the system can answer from a controlled set of public documentation pages.
At a high level, the flow looks like this:
- infer or extract the user’s intent
- resolve that intent to one or more known public URLs
- pass those URLs into a Live Search LLM action
- generate a grounded response based only on those selected sources
This avoids the need for a separate scraper or content gateway while still keeping the answer tied to public documentation.
The accessibility use case is a good example, but this pattern is generalizable to any public documentation domain where the source set is known or can be constrained.
Important Limitation
A key limitation to call out is that this pattern should be treated as source-page grounded, not as a broad crawler.
In other words:
- it should not assume it will follow and scrape arbitrary embedded links from a page
- it works best when the relevant source URLs are already known, resolved ahead of time, or selected from a controlled list
- if deeper coverage is needed, that additional url set should be explicitly defined as part of the architecture
This is important because it changes how the solution should be designed. If the action only grounds against the provided source material, then the quality of the experience depends heavily on how well the system chooses the right URLs up front.
Two Architectural Patterns
Pattern 1: Static URL Resolution
The simplest pattern is to predefine the URLs and trigger logic per application or documentation area.
For example, instead of sending all Microsoft accessibility traffic to one top-level page, the workflow can map more specific intents to more specific URLs.
A user question about Teams closed captioning could resolve directly to a page such as:
https://www.microsoft.com/en-us/microsoft-teams/accessibility-closed-captions-transcriptions
In this model, the architecture relies on:
- a predefined list of supported URLs
- explicit mapping between user intents and those URLs
- tightly designed triggering so the right URL can be inferred
Why use this pattern
This works well when:
- the supported source pages are known in advance
- the domain is relatively stable
- the question types are predictable
- precision matters more than broad discovery
Tradeoff
The downside is maintenance. The architecture becomes more granular per application, feature area, or documentation topic, and the team must define both:
- the list of URLs
- the likely triggering patterns or intent mappings
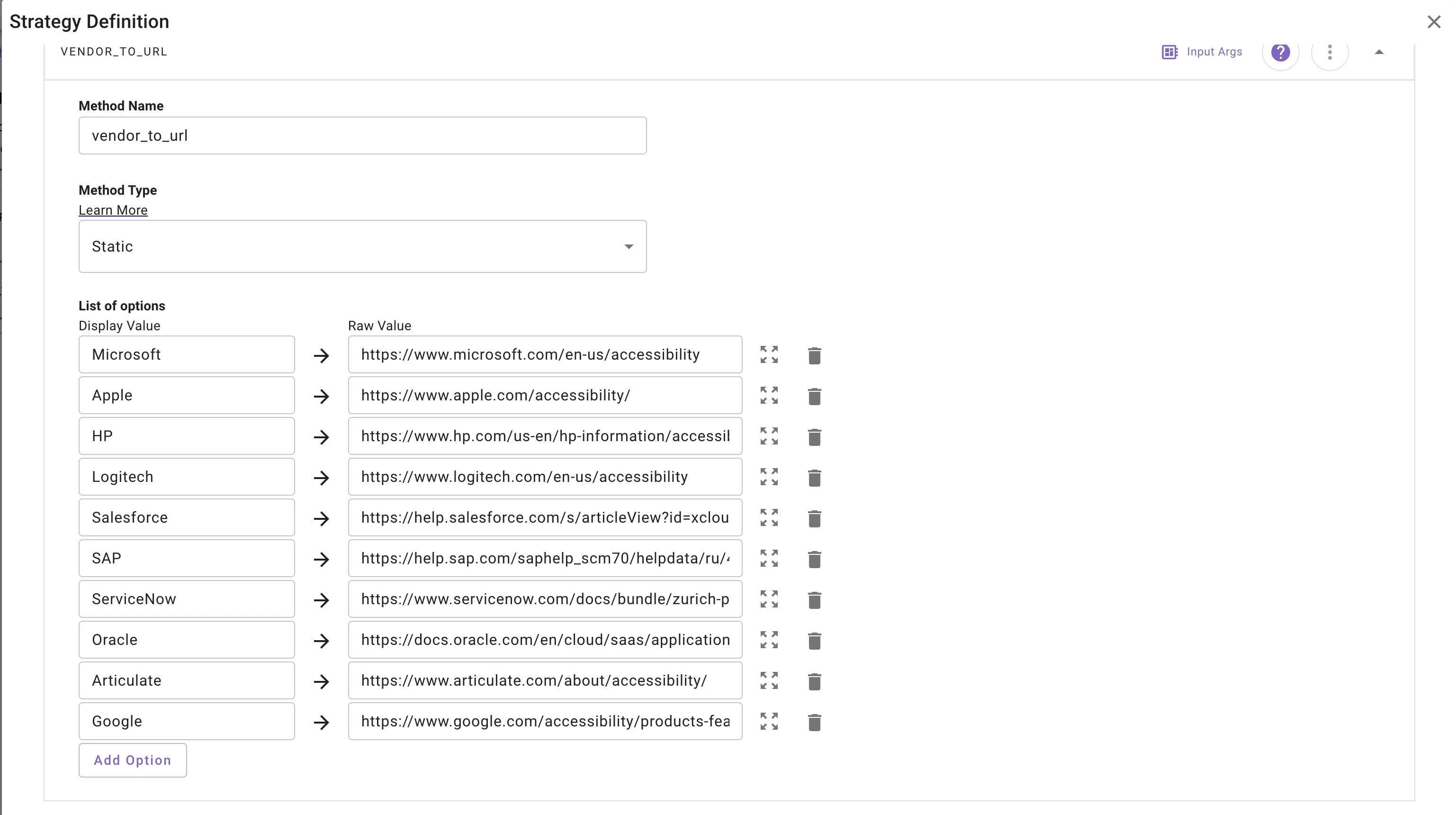
Pattern 2: Dynamic URL Resolution from a Controlled List
A more flexible variation is to keep a predefined corpus of allowed URLs, but use an LLM action to choose the best ones dynamically based on the user’s intent.
In this model:
- a structured data LLM action receives the user’s application and intent
- it searches or fuzzy-matches against a predefined list of URLs
- it returns the top 3 or top N relevant URLs
- a second Live Search LLM action uses those URLs as the grounding set for the final response
This lets the architecture stay controlled while reducing the need to hand-author every possible trigger-to-URL mapping.
The URL list itself can come from:
- a manually defined list
- a curated sitemap
- a structured catalog of approved documentation links
Example Dynamic Resolver Design
One way to implement the resolver is to use a structured data action that returns a small list of relevant URLs.
Example schema:
model:'"gpt-4.1-2025-04-14"'
output_schema:|-
{
"type": "object",
"properties": {
"urls": {
"type": "array",
"description": "A list of up to 3 highly relevant URLs from the prompt below",
"items": {
"type": "string"
},
"maxItems": 3
}
},
"required": ["urls"],
"additionalProperties": false
}
payload:
app: data.application
intent: data.intent
system_prompt:
RENDER():
args:
sitemap: data.sitemap
template: Select the most relevant URLs given the Intent from what the user is asking about from the list below and
return those chosen. {{sitemap.urls}}
In this design, the first action does not answer the user directly. Its job is only to select the most relevant URLs from the approved set. Then a second Live Search action uses those selected URLs as the grounding input for the final answer.
Example: Accessibility Documentation
Accessibility documentation is a useful example because it often spans multiple pages within a vendor’s public documentation set.
A broad top-level URL might be enough for general questions, but feature-specific questions are often better answered from specific pages.
For example:
- Application: Microsoft Teams
- Intent: closed captioning
- Resolved URL: Microsoft Teams accessibility closed captions and transcriptions page
In a static model, that URL is explicitly mapped ahead of time.
In a dynamic model, the question is classified, matched against a controlled Microsoft accessibility URL set, and the best few URLs are returned for grounding.
This makes the architecture more scalable while still keeping it bounded to trusted public pages.
Key Decisions
1. Decide whether URL selection is static or dynamic
The first major design choice is whether the workflow should use fixed mappings or LLM-based URL selection from a predefined list.
Static resolution is better when the problem space is narrow and predictable.
Dynamic resolution is better when the source set is larger and the user’s phrasing may vary.
2. Keep the source set controlled
Even in a dynamic model, the LLM should choose from a known list of URLs rather than from the open web.
This preserves reliability and makes the architecture easier to validate.
3. Separate URL selection from answer generation
Using one action to select URLs and another to answer from them creates a cleaner architecture.
This separation improves debuggability and makes it easier to tune the system over time.
4. Design for source-page grounding, not open crawling
If the architecture only grounds against the supplied URLs, then the workflow must be intentional about what those URLs are.
That means the page inventory matters just as much as the prompt design.
5. Make intent extraction explicit
The better the system can identify the user’s true intent, the better it can select the right pages.
This is especially important when the same application has many related documentation pages.
Things to Consider
This approach does not automatically cover embedded links
If relevant information lives on child pages or related linked documents, those pages should be explicitly included in the URL set. Otherwise, the answer may only reflect the contents of the main source page.
Granularity drives maintenance
The more specific the experience needs to be, the more likely the architecture will need a larger and more detailed URL inventory.
For example, “Microsoft accessibility” is easy to map broadly, but “Teams closed captioning accessibility” benefits from feature-level URL resolution.
Dynamic selection still needs boundaries
An LLM-based resolver can improve flexibility, but it should resolve only from an approved list. Otherwise, consistency and trust become harder to maintain.
Sitemap quality matters
If the architecture uses a sitemap or catalog of URLs, that source must be curated enough to avoid noise and outdated pages.
Prompting still matters
The answer-generation prompt should clearly instruct the model to use only the supplied sources and provide citations when appropriate.
This pattern is best for bounded public documentation
It is strongest when the domain is well understood, the source list can be controlled, and the expected question types are reasonably predictable.
!-->
